gitGraph: commit id: "A" commit id: "B: remove code/analysis.R" commit id: "C" commit id: "D (HEAD)" commit id: "git checkout A code/analysis.R" type: HIGHLIGHT commit id: "E: add analysis back"
Advanced Statistical Programming using R
Week 4: Version Control & Collaborative Coding
2026-05-07
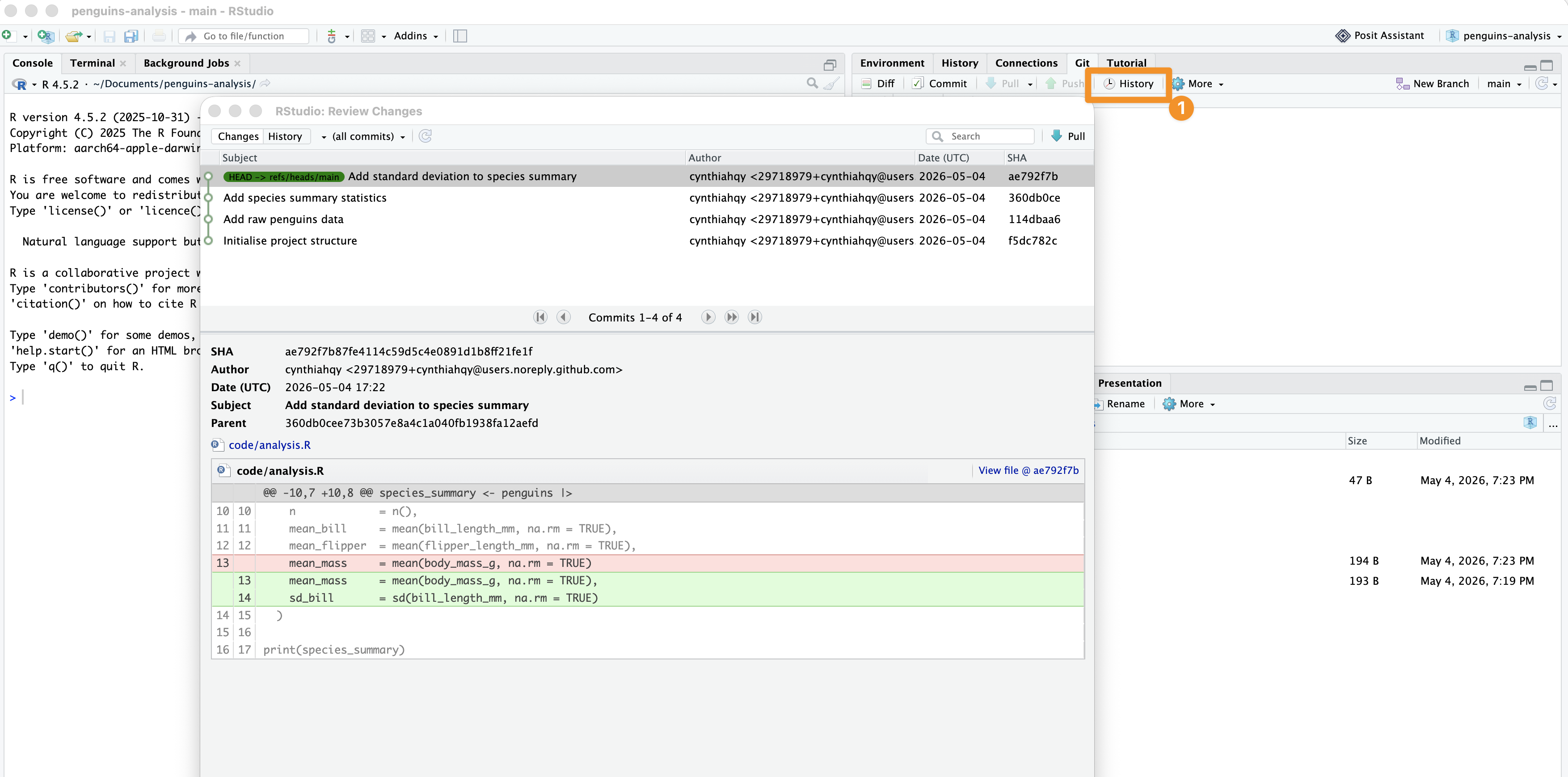
In RStudio: view log
Tip
The RStudio Git History panel calls git log under the hood — you can also run git log --oneline in the terminal for a compact view.
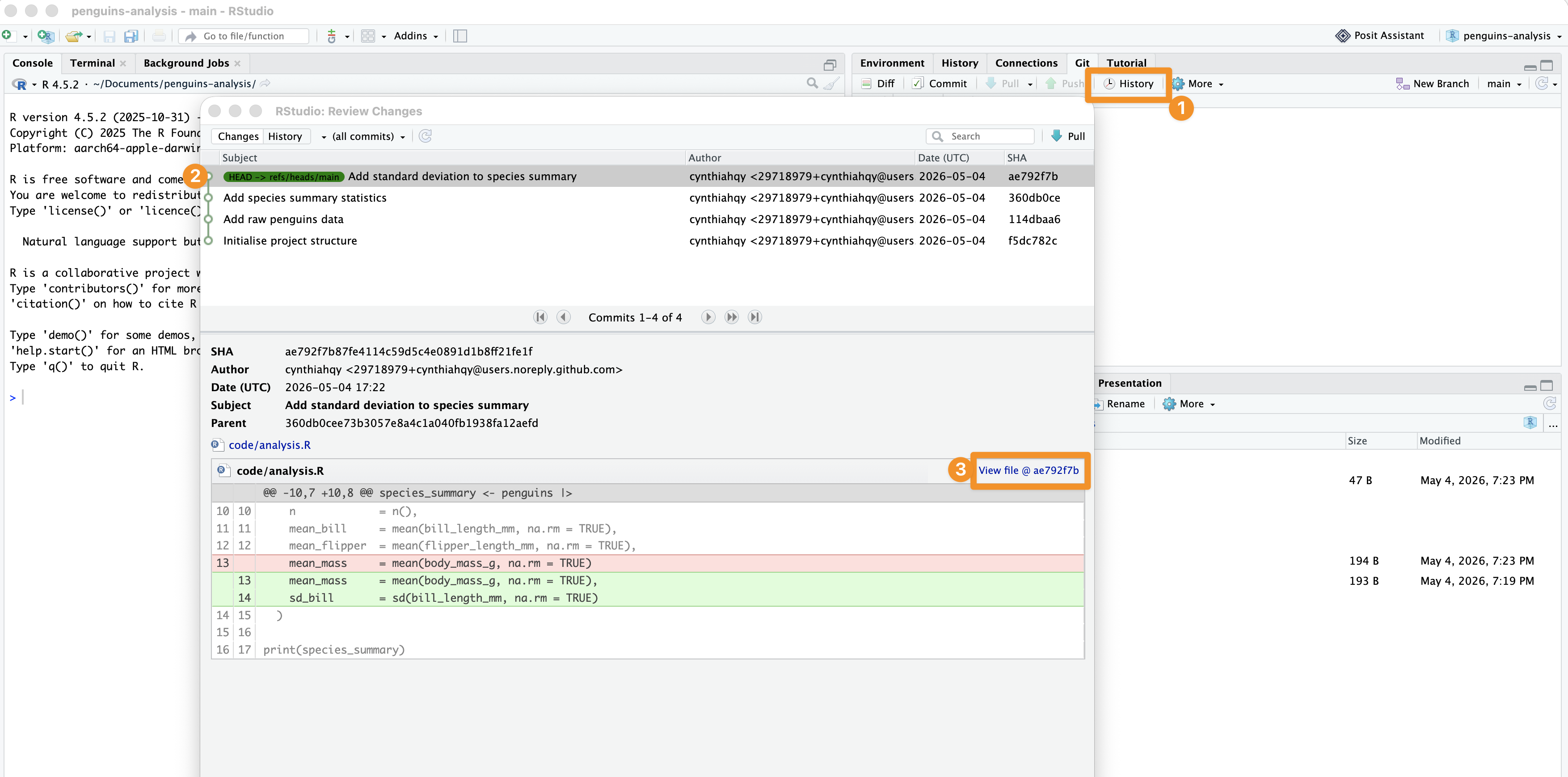
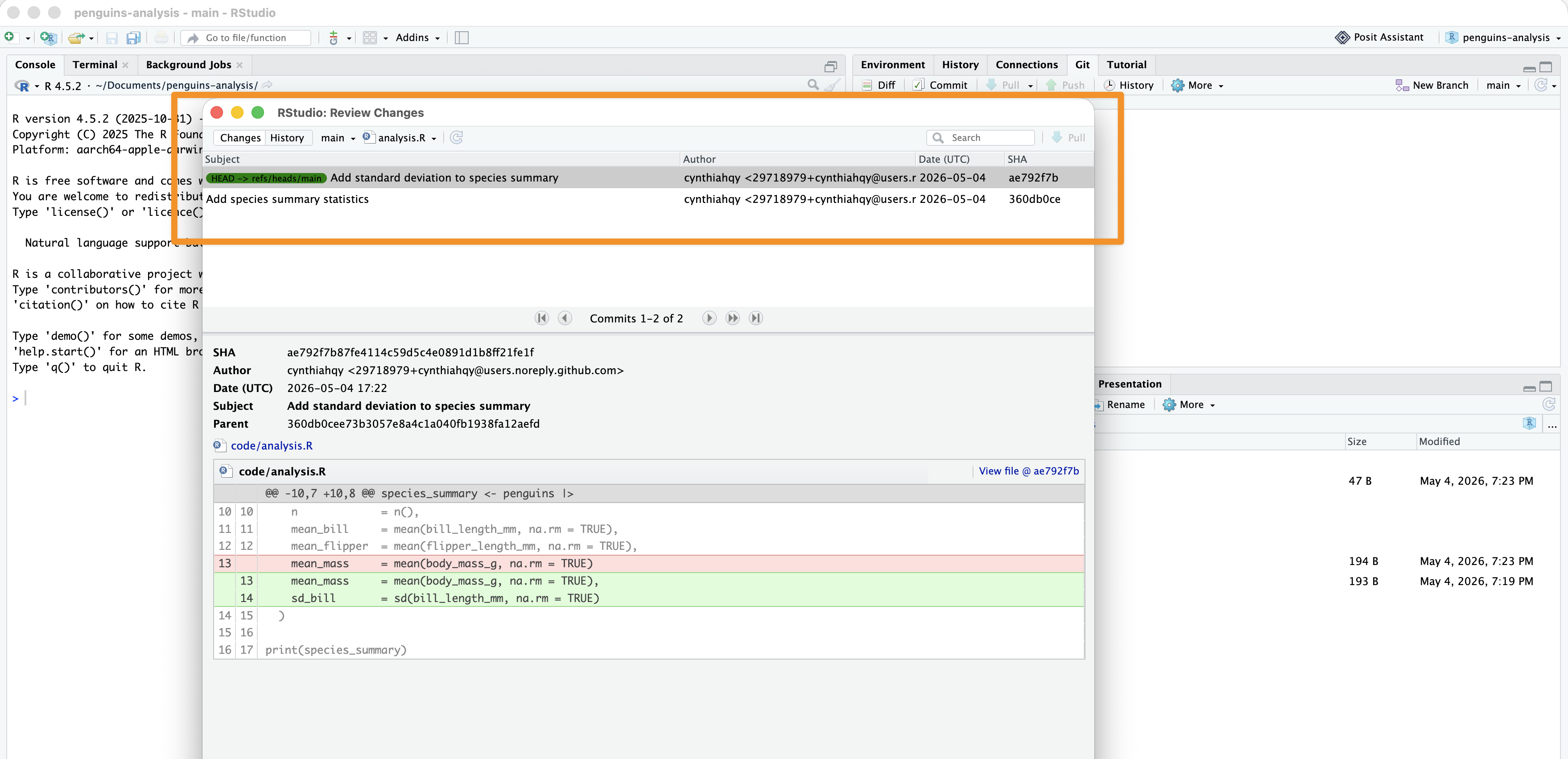
In RStudio: see changes
Tip
Changes are shown as highlights: red for deletions and green for additions
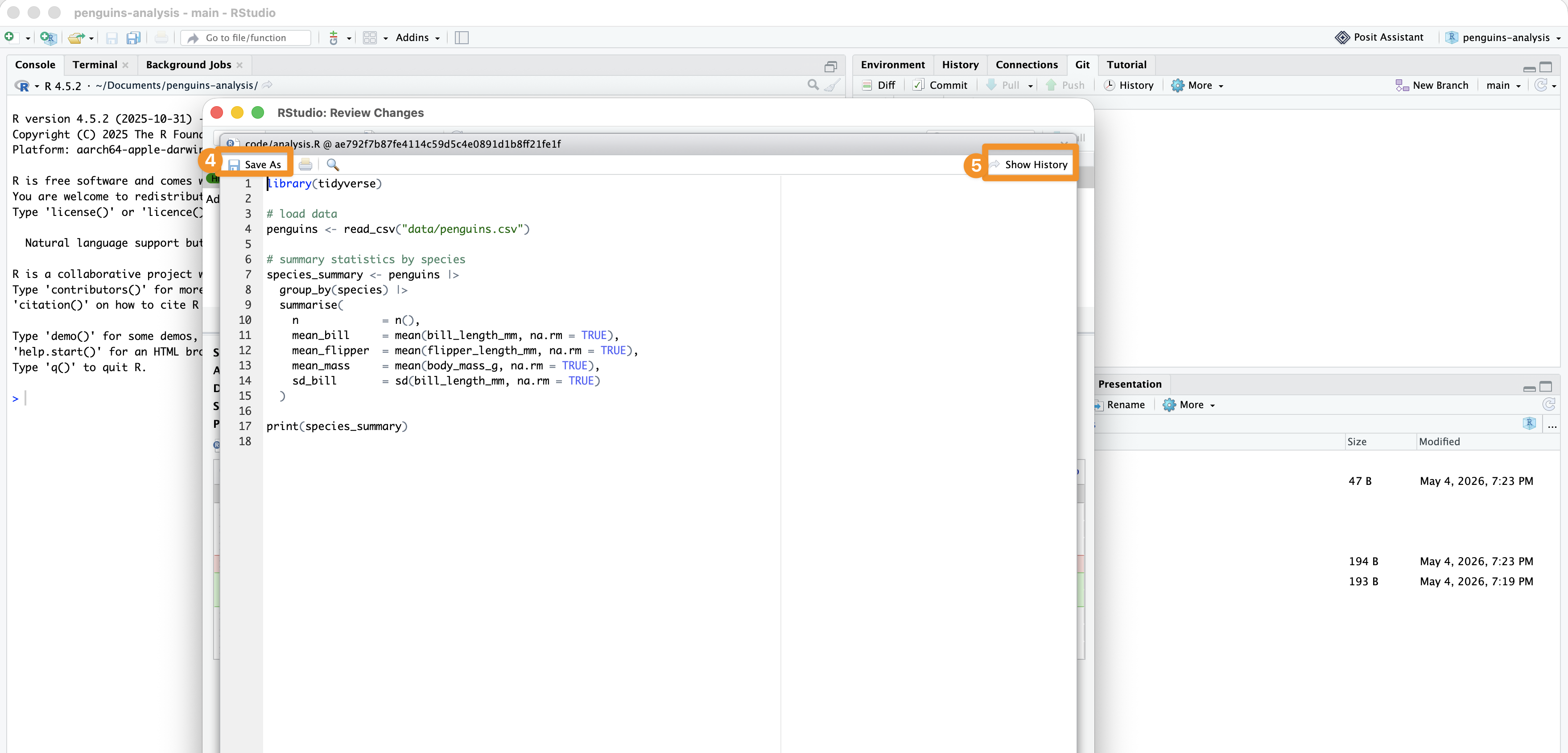
In RStudio: save past versions
Tip
Rstudio is displaying the results of: `git checkout
In RStudio: view file history
CLI: Restore removed files
3. Revert the offending commit`
git revert <hash>gitGraph: commit id: "A" commit id: "B: remove code/analysis.R" type: REVERSE commit id: "C" commit id: "D (HEAD)" commit id: "git revert B" type: HIGHLIGHT commit id: "E: add analysis back"
Auto-commits — done!
If we use the ‘Save As’ button in RStudio to restore the file, which option are we in?
- 1:
git diff <B> <A>| git apply - 2:
git checkout <A> -- <file> - 3:
git revert <B>
ASIDE: How does git actually work?

Fork an existing repository
Navigate first to the repository you want to fork – e.g.:
🔗 github.com/soda-lmu/our-statprog2-project
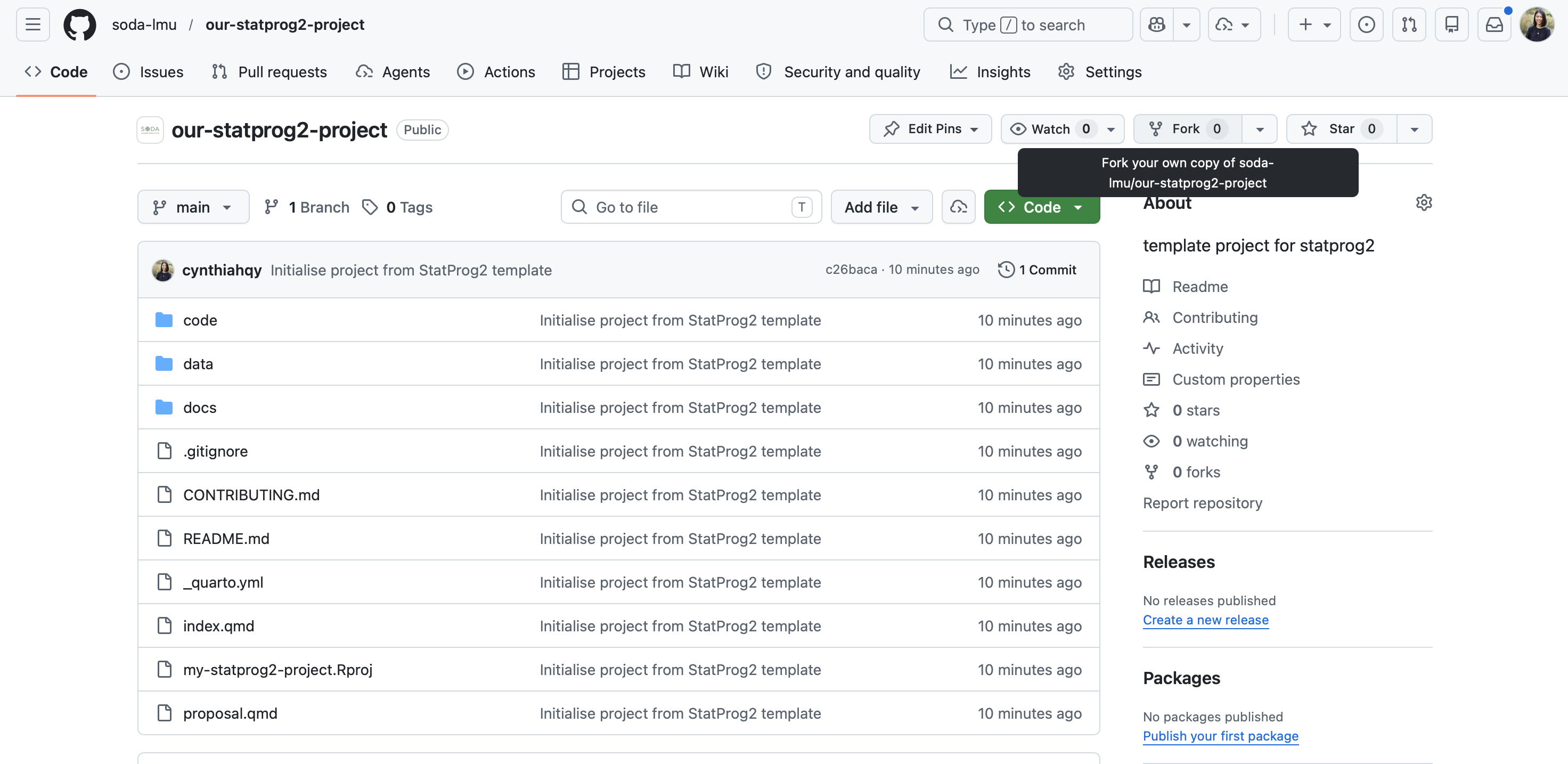
Fork an existing repository
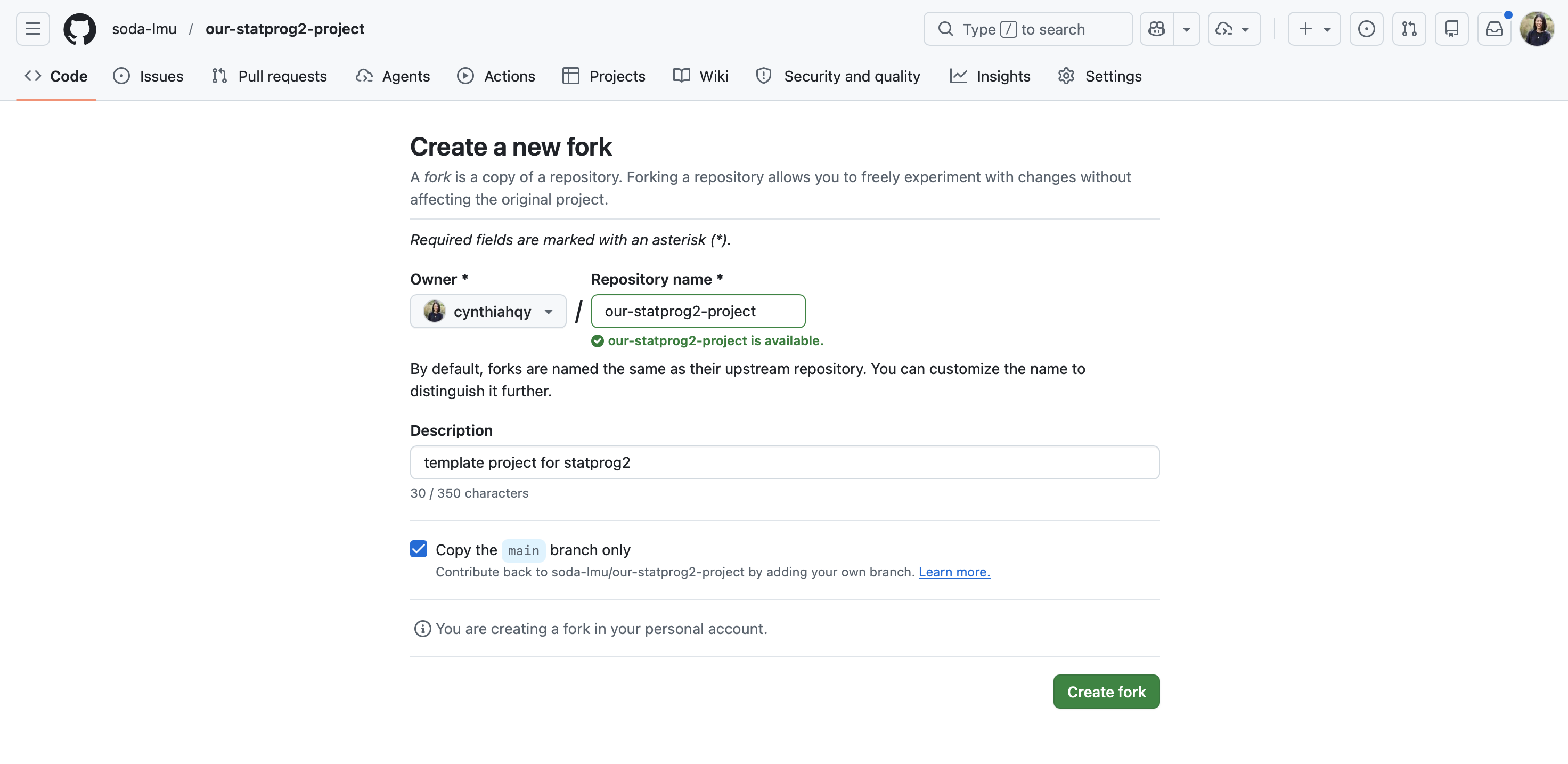
Give your fork a name
Fork an existing repository
Forking in progress
Fork an existing repository
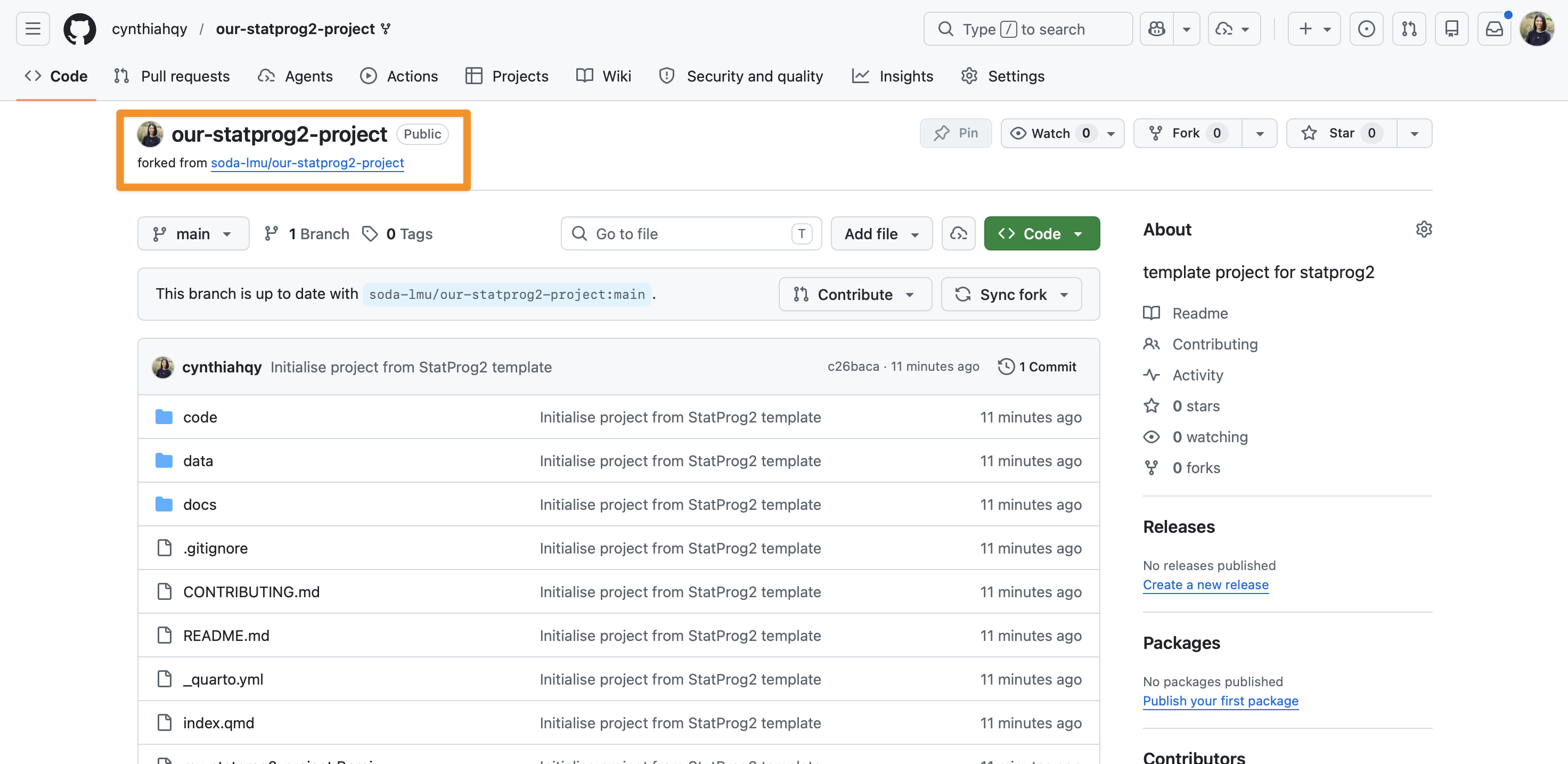
Notice the connection to the original repository
Clone an existing repository
Clone to your machine – automatically sets the remote.
git clone <url> # copy a repo to your machine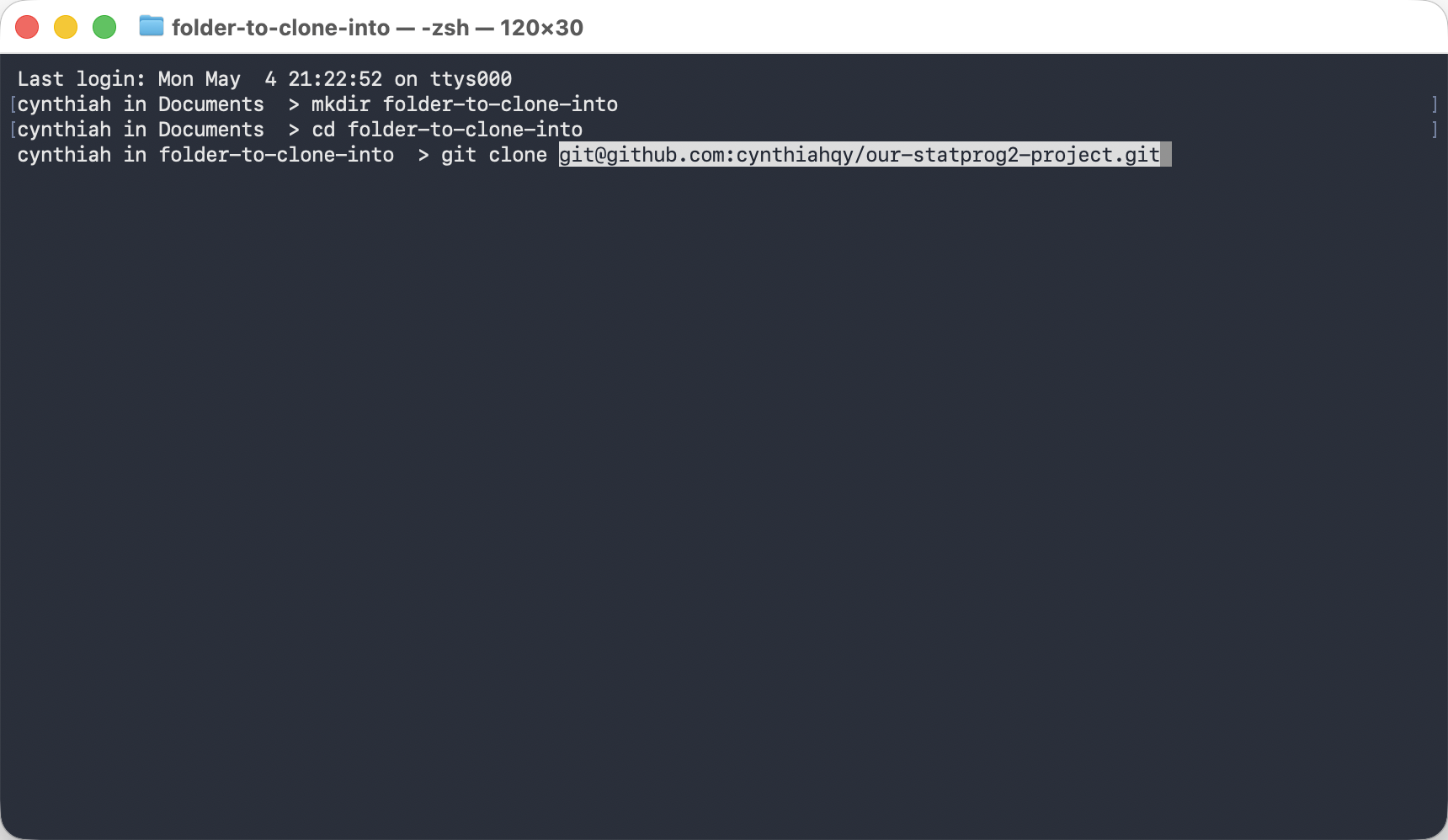
Clone an existing repository
Getting the URL
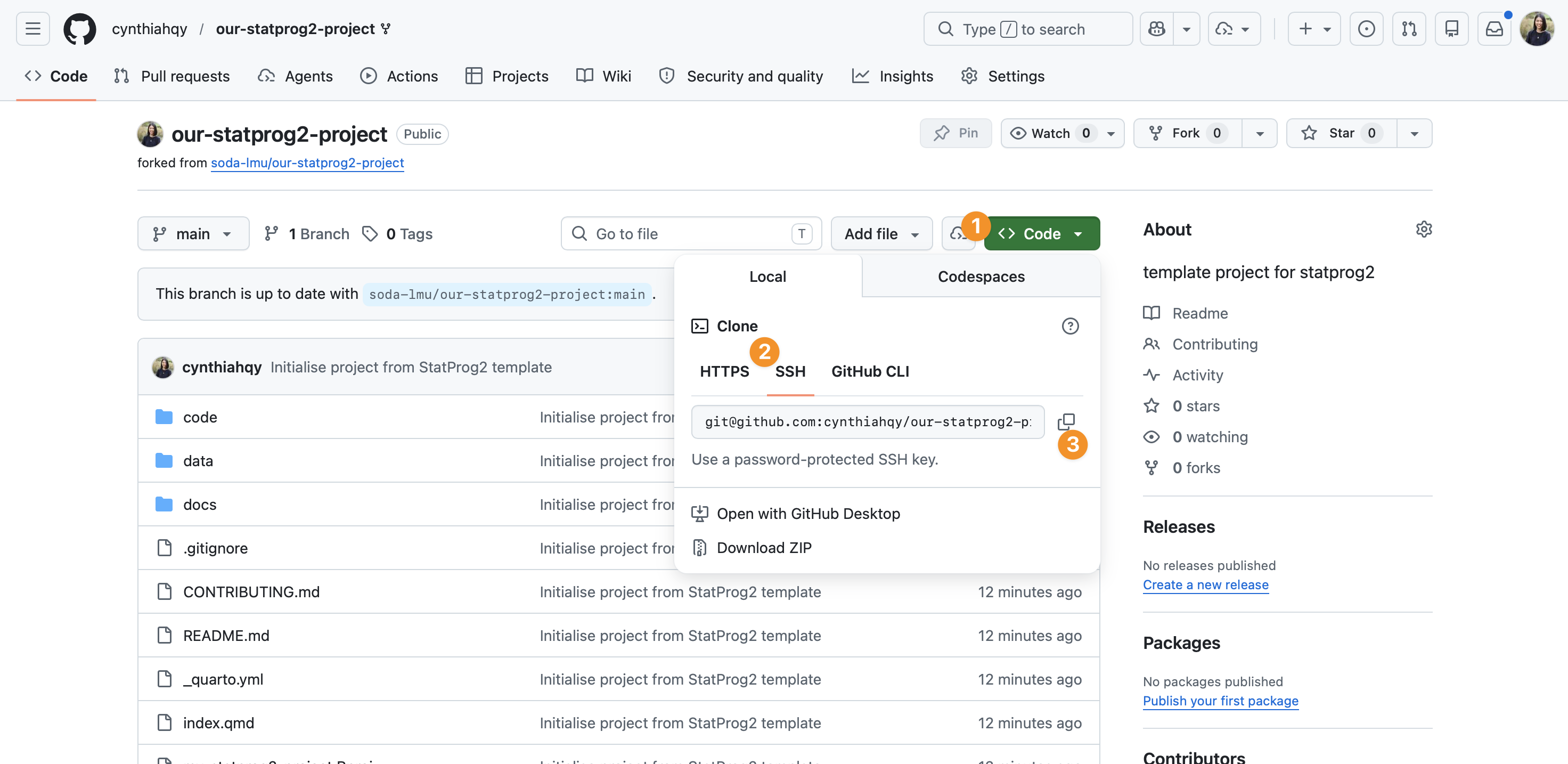
Clone an existing repository
Clone to your machine – automatically sets the remote.
git clone <url> # copy a repo to your machine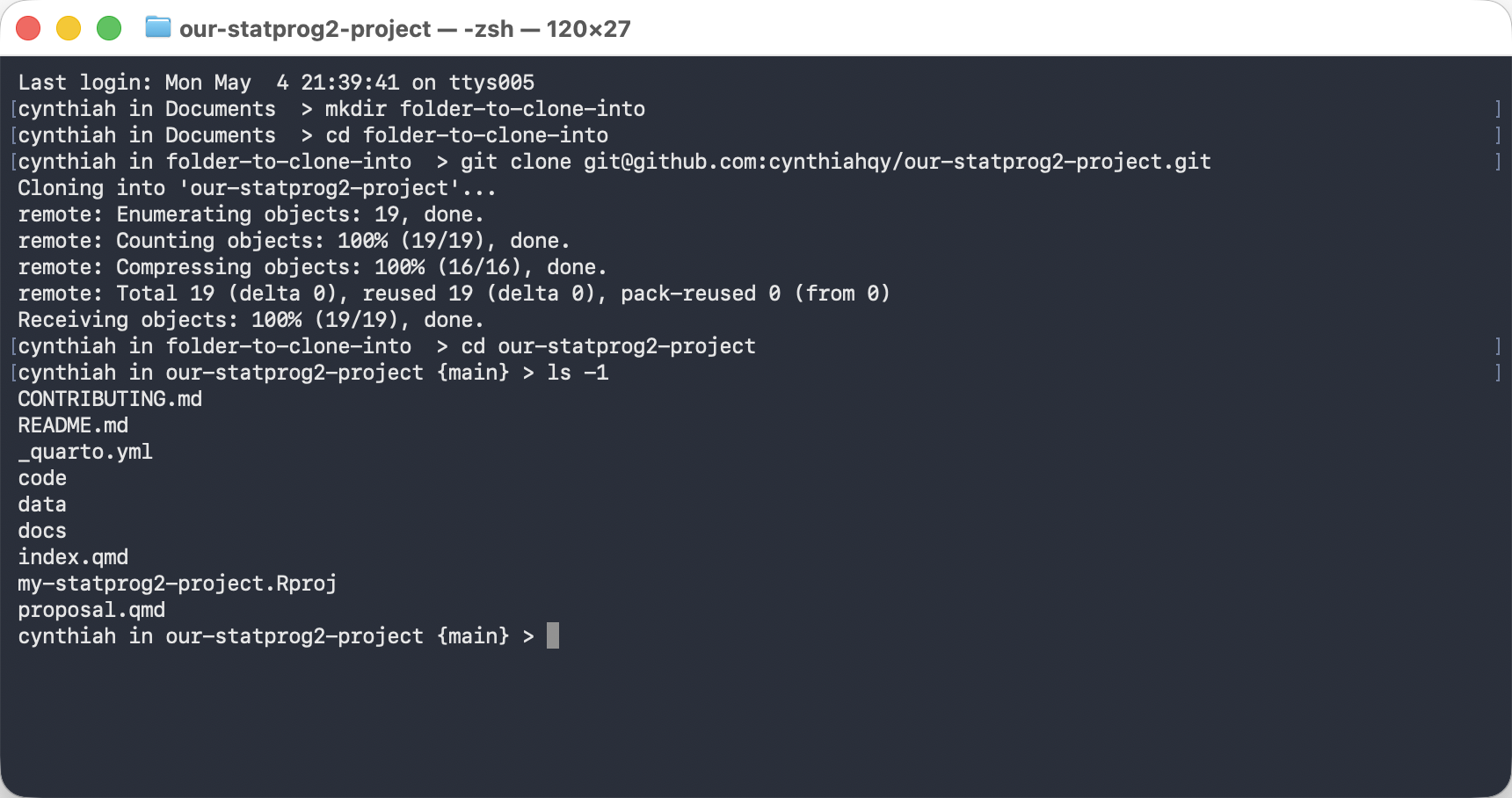
In RStudio: Edit
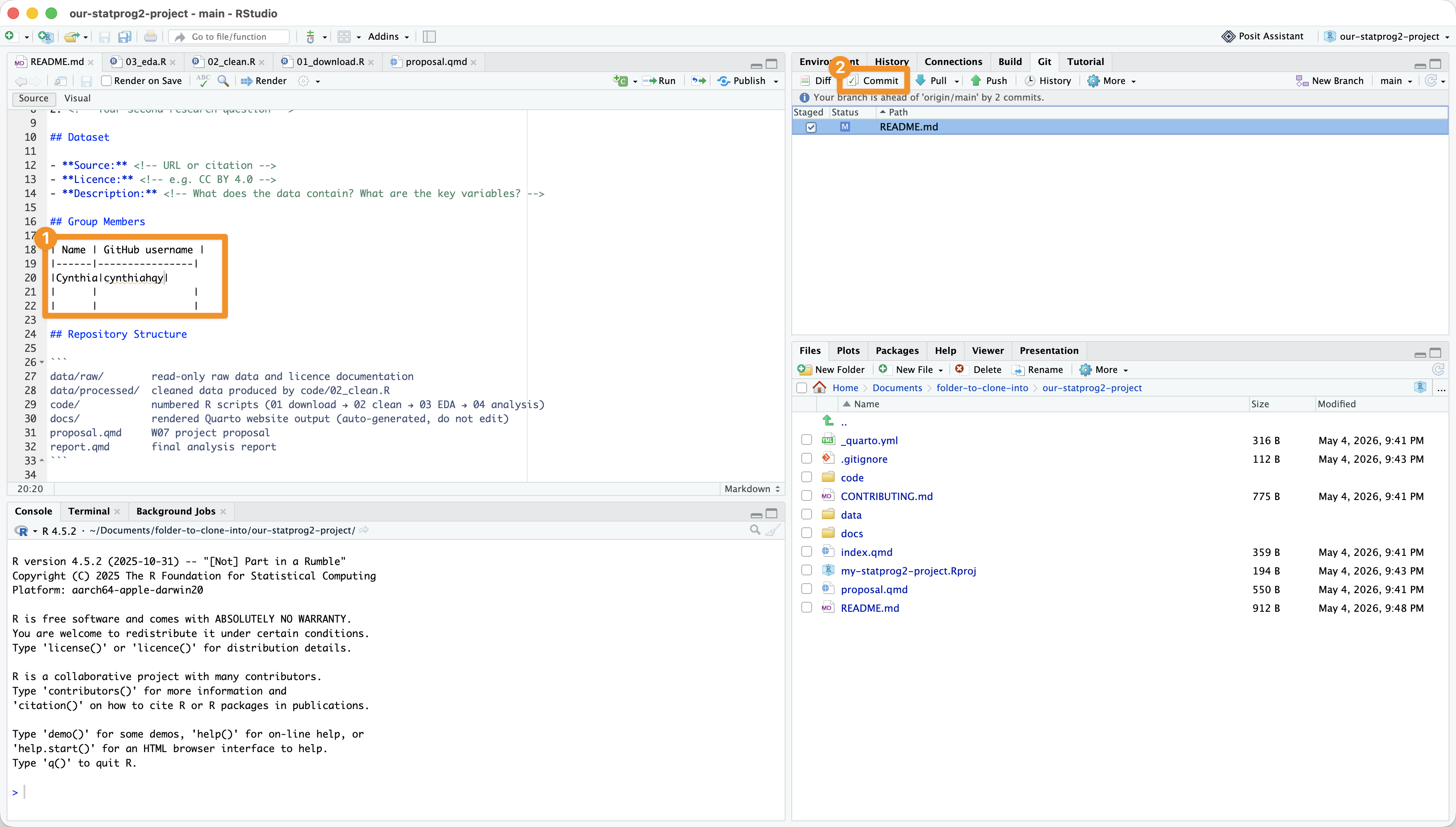
In RStudio: Commit
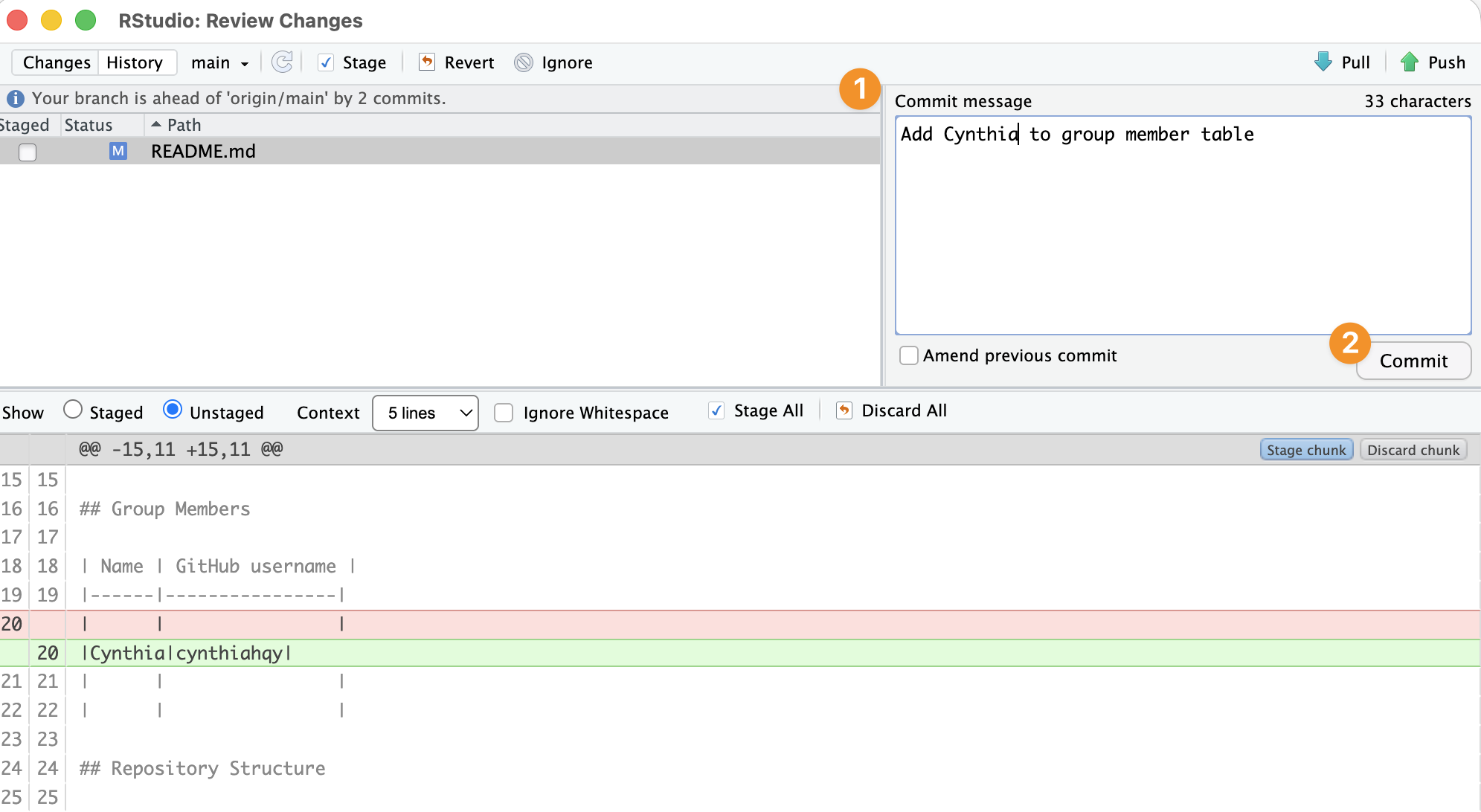
What CLI commands is RStudio performing for you?
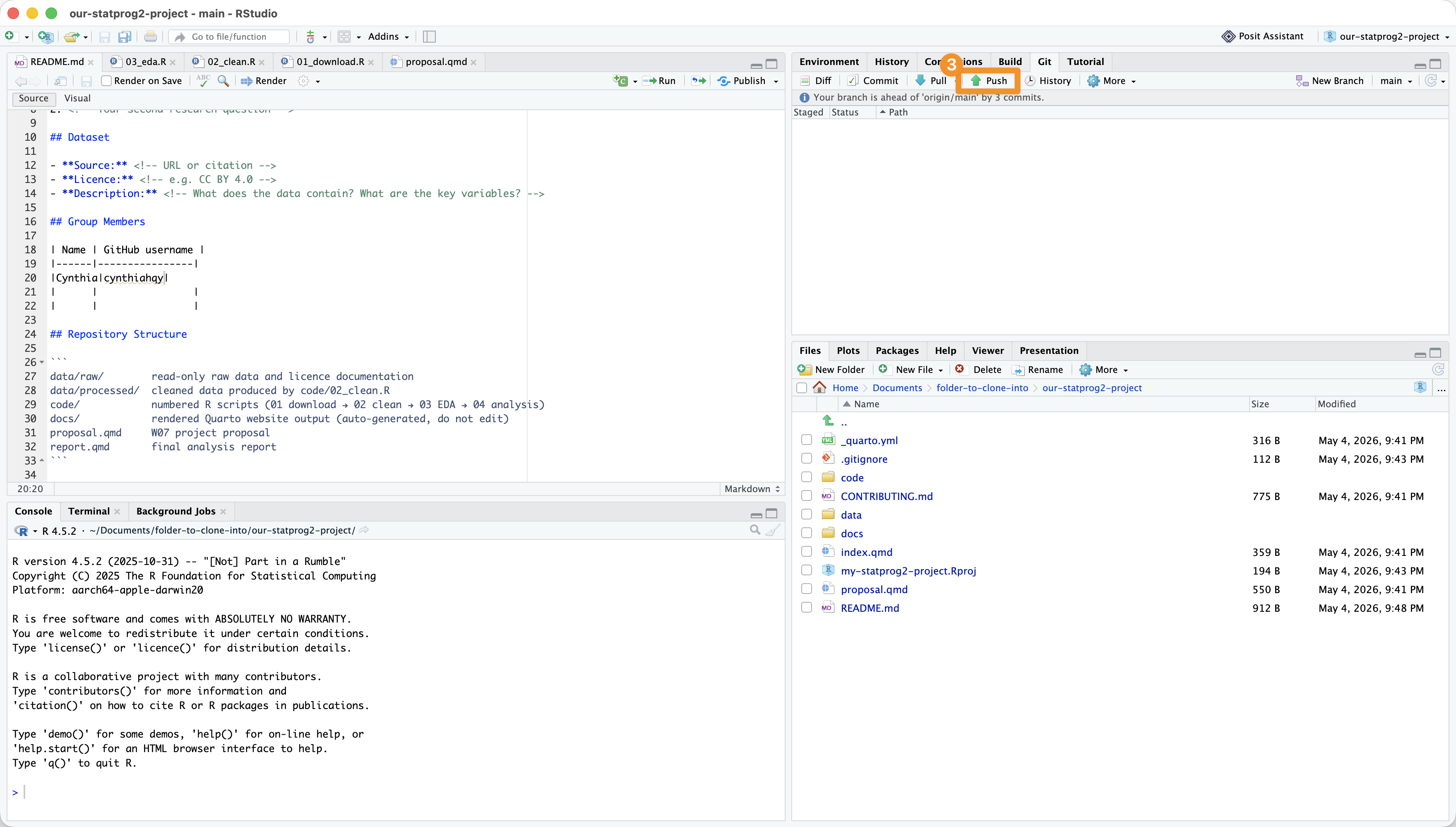
In RStudio: Push
In RStudio: Rejected Push???
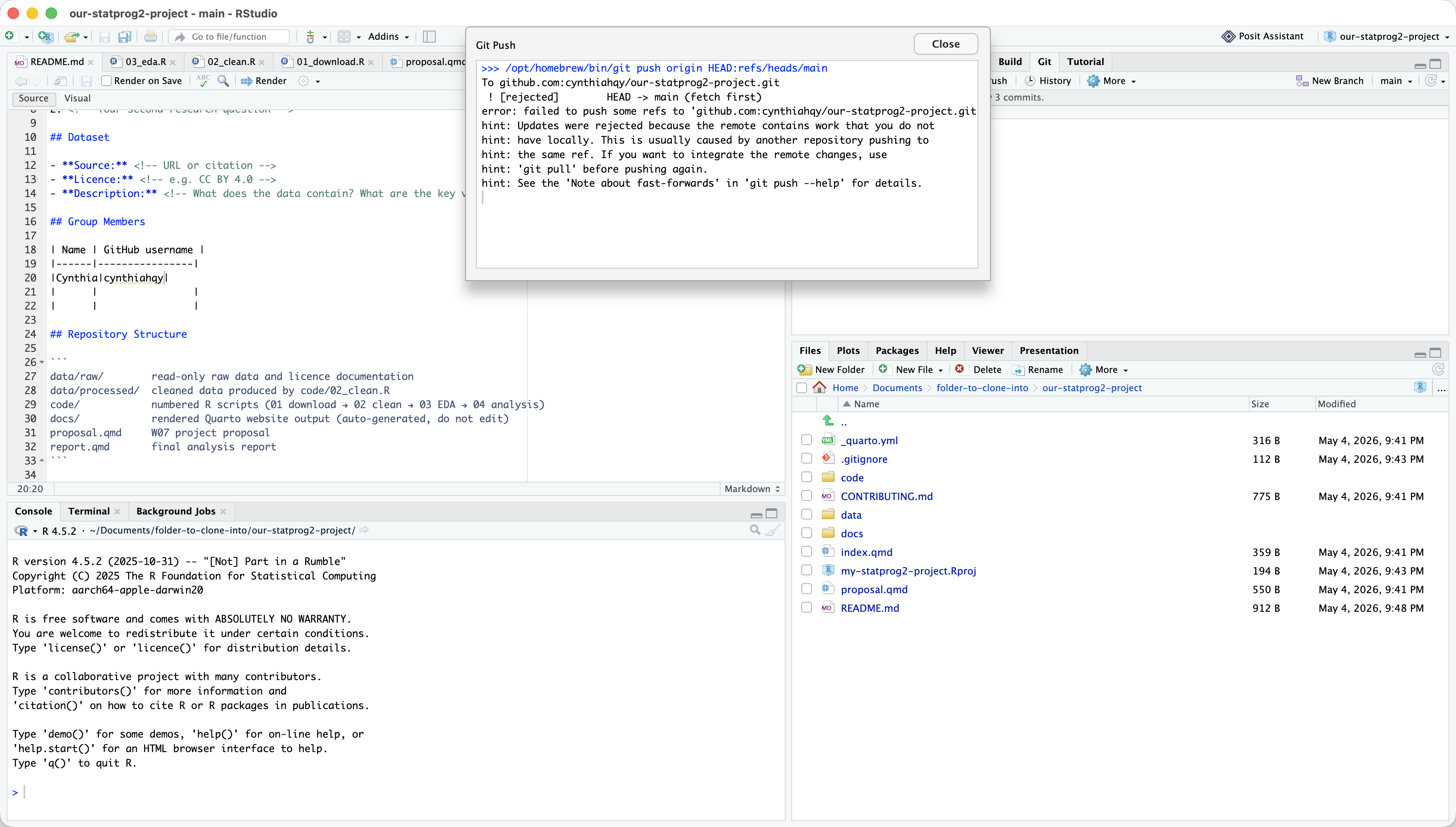
In RStudio: Pull THEN Push
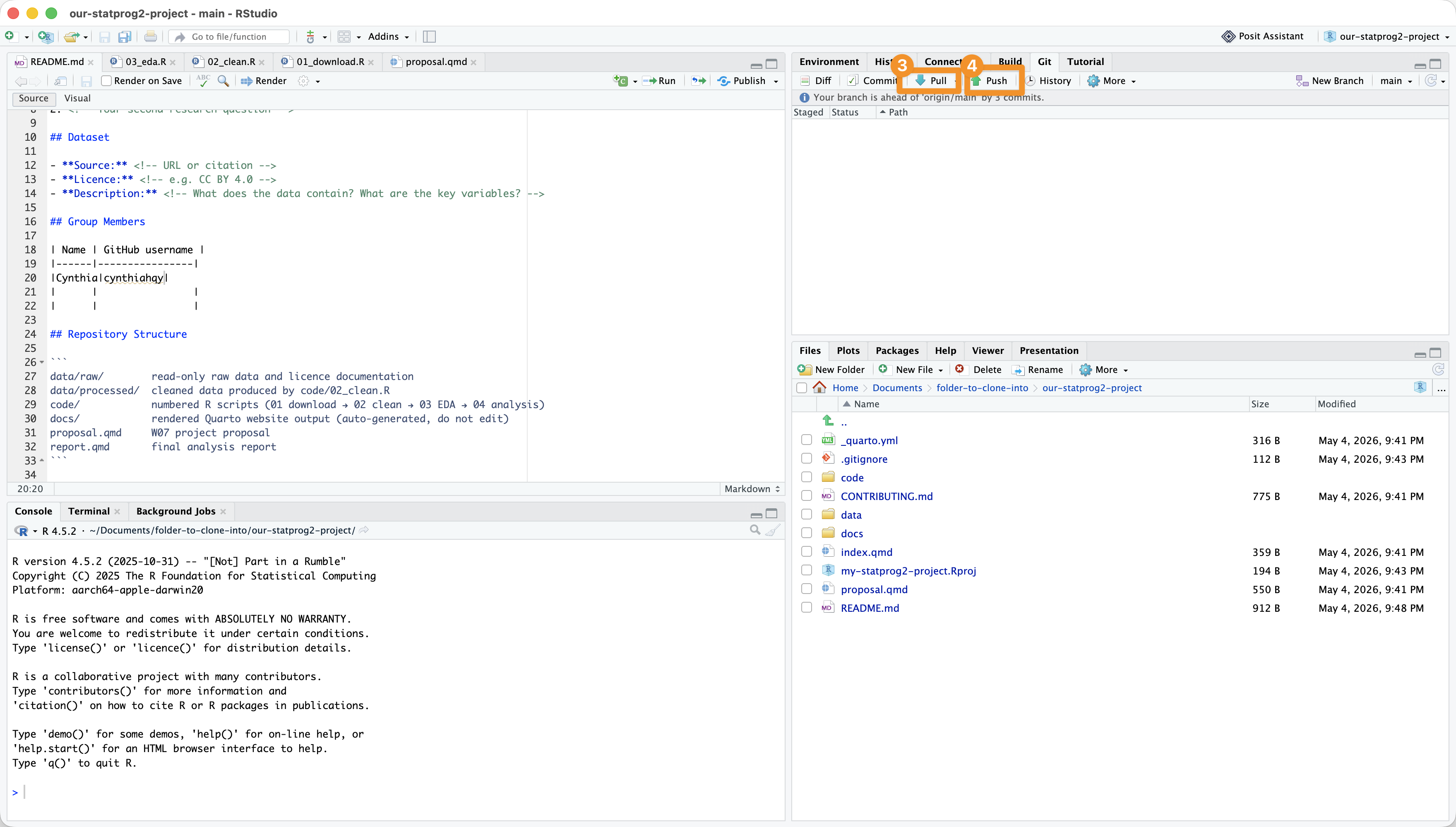
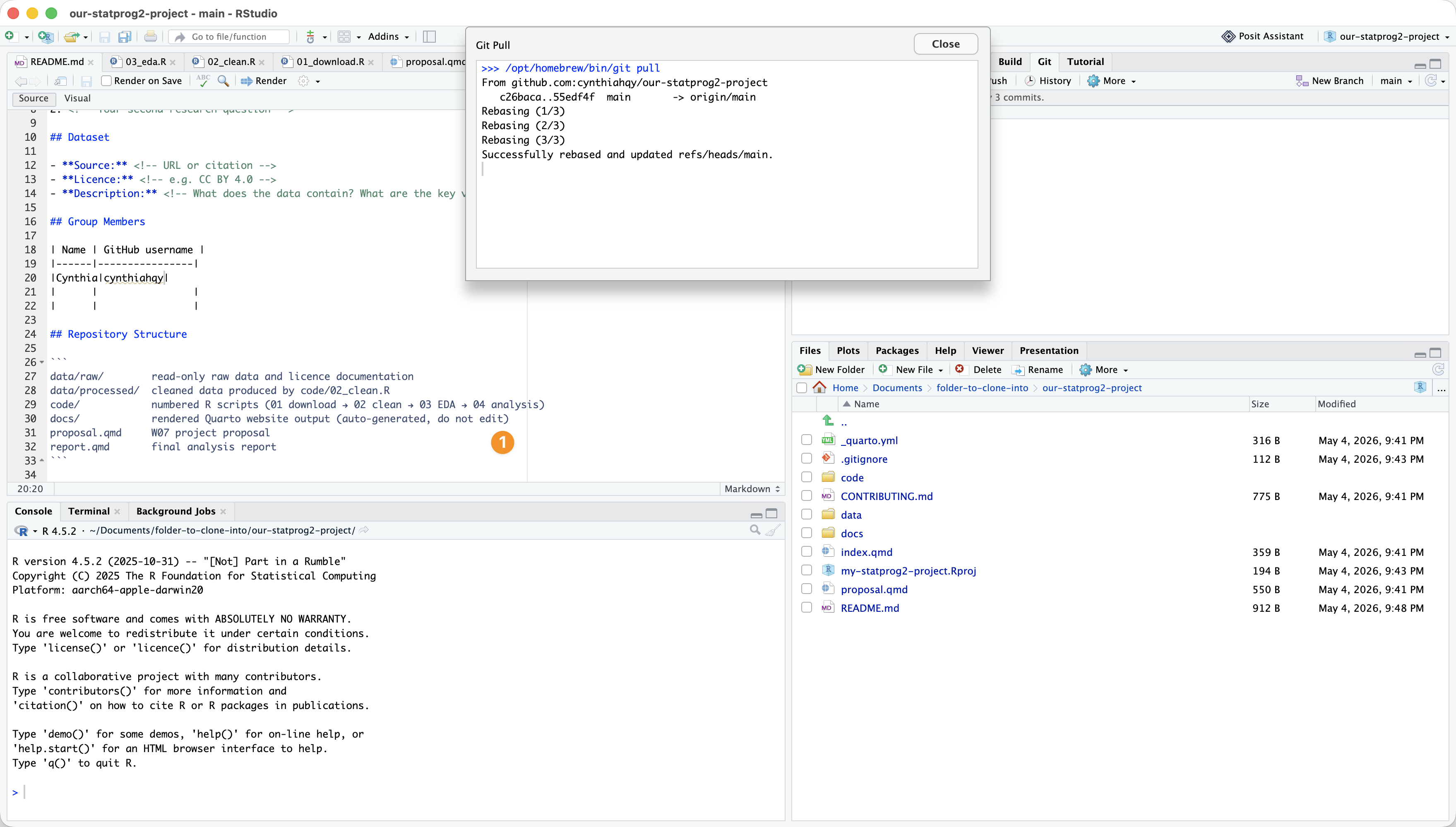
In RStudio: Success!
Pushing an existing repository?
Let’s say you have a repository on your local machine, and you want to git push it to GitHub
You can’t push without a remote!
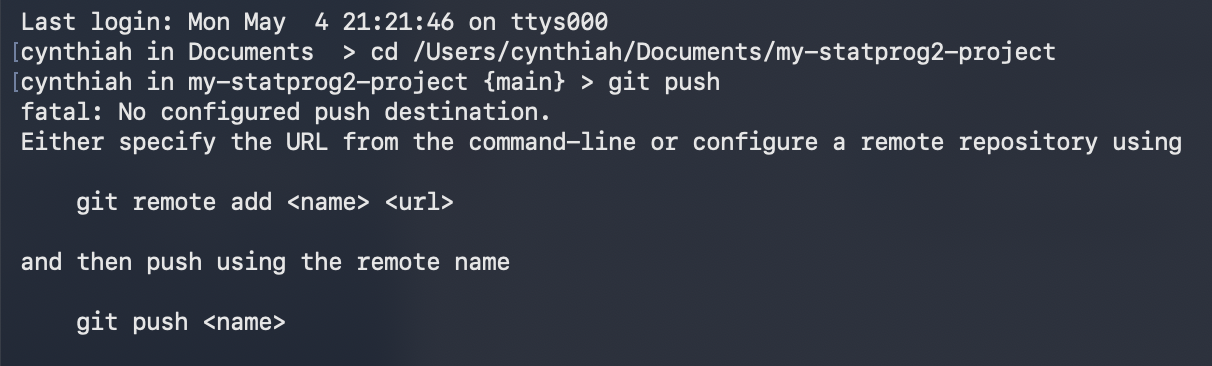
So we need to set up a remote repository to connect to!
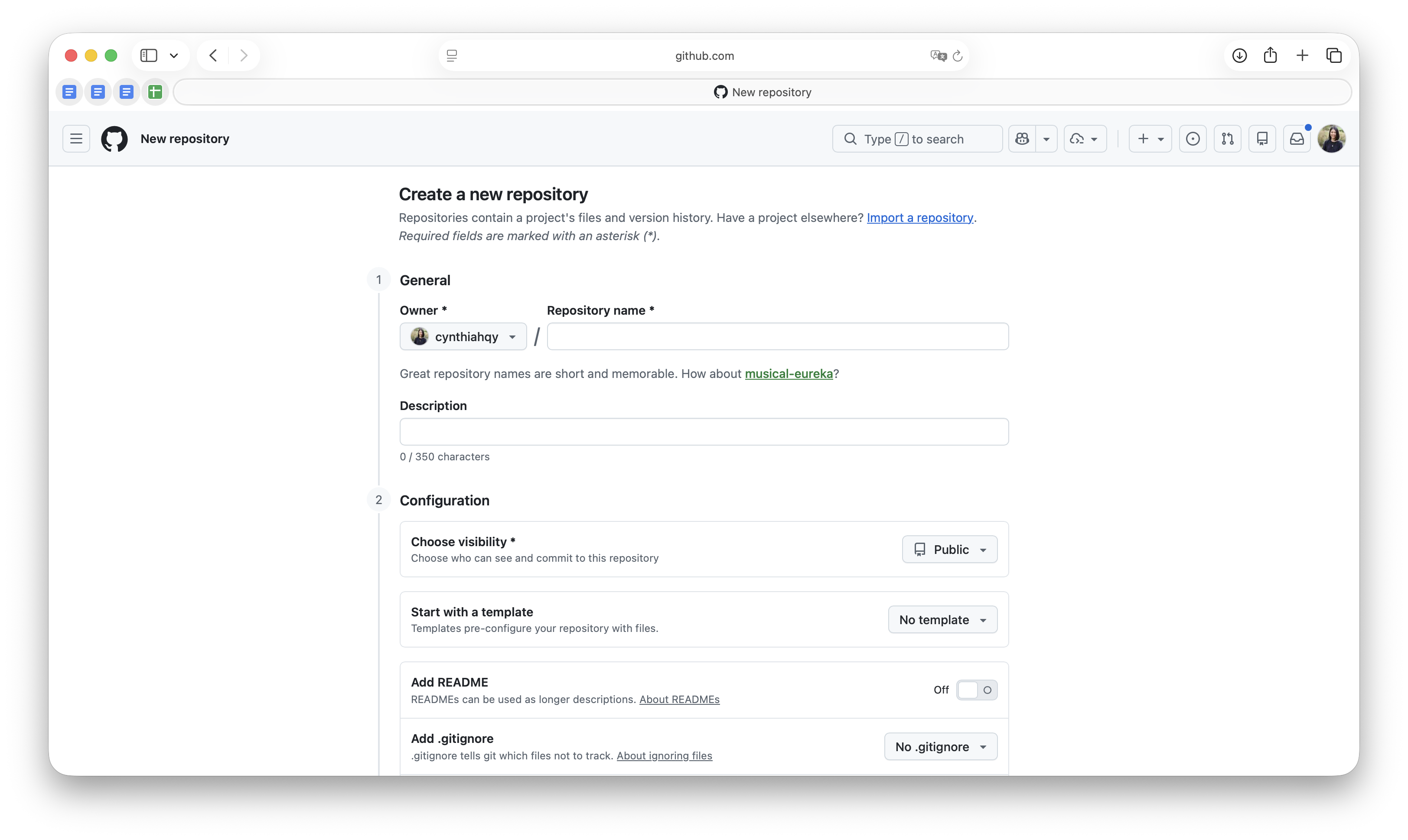
GitHub: Creating a new repo
GitHub: Creating a new repo
Extension: GitHub CLI
The GitHub CLI (gh) lets you create repos without leaving the terminal.
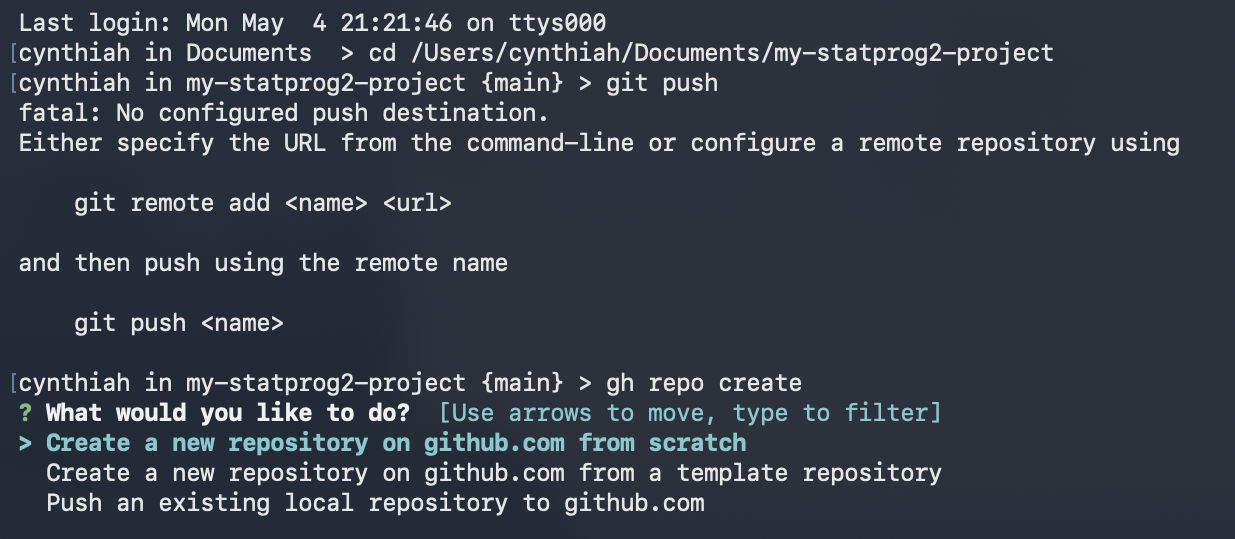
Extension: GitHub CLI